Building the monitoring surface worth switching to.
- Systems Design
- Migration
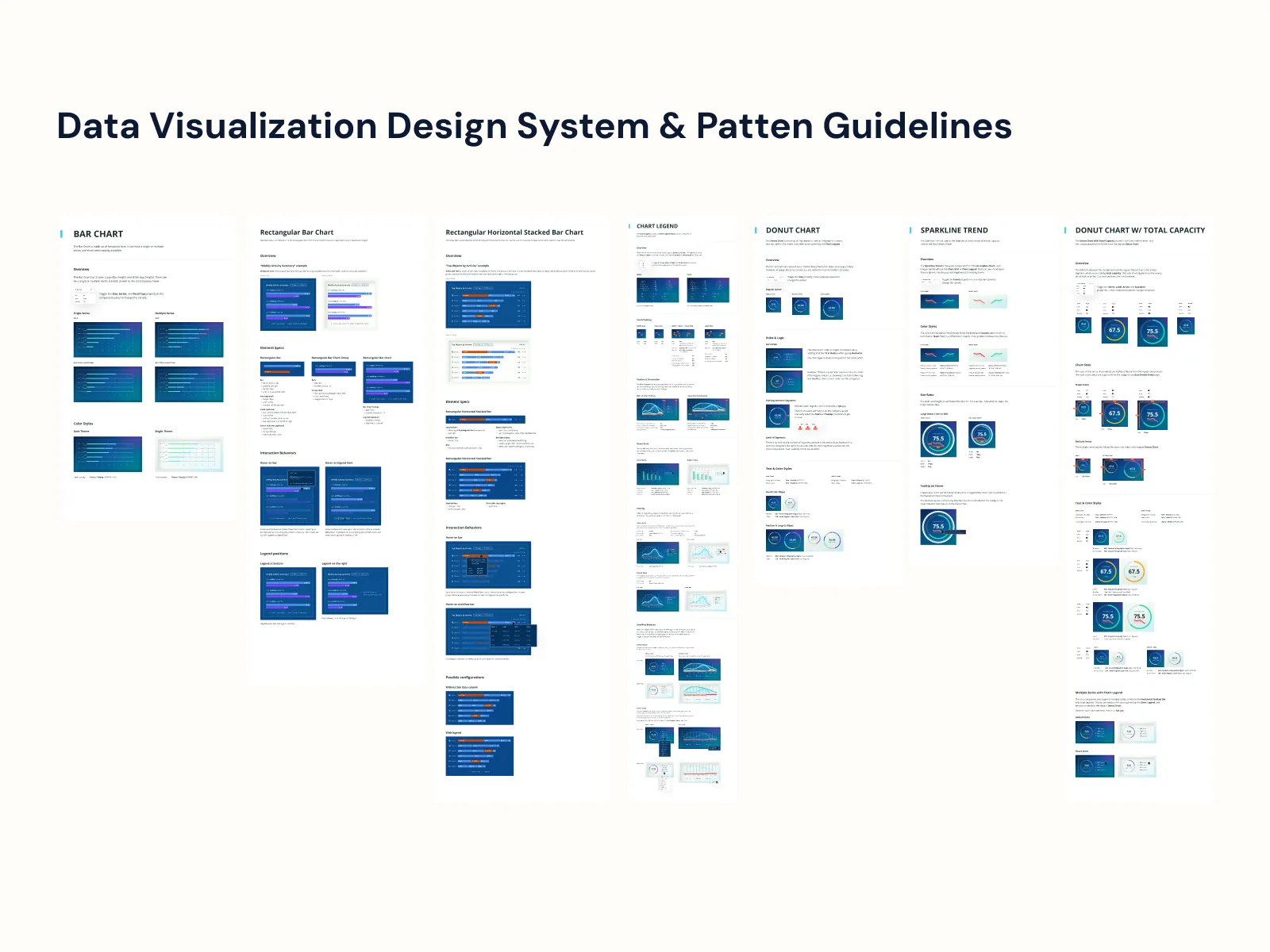
- Data Viz
- CLI → UI
Rubrik makes the data infrastructure that backs up enterprise systems and recovers them after ransomware, hardware failure, and outages. The people who run that infrastructure — IT and data admins — spend their days inside a monitoring console: watching cluster health, queueing backup jobs, replacing failing disks, chasing alerts. Rubrik had built a new cloud version of that console (Rubrik Security Cloud) but day-to-day monitoring was still mature on the old on-prem tool, and 85% of customers hadn't migrated. I led the systemic redesign that gave them a reason to move without breaking the muscle memory their jobs depend on.
- Role
- Senior Product Designer
- Timeline
- Mar 2022 — May 2023
- Team
- 5 PMs · 2 PDs · 18 engineers
- Tools
- Figma, User Research, Design Systems
Most of my work lives behind NDAs and embargoes. The walkthrough that matters — the why, the things I cut, the calls I'd make differently — happens in conversation, not on a page.
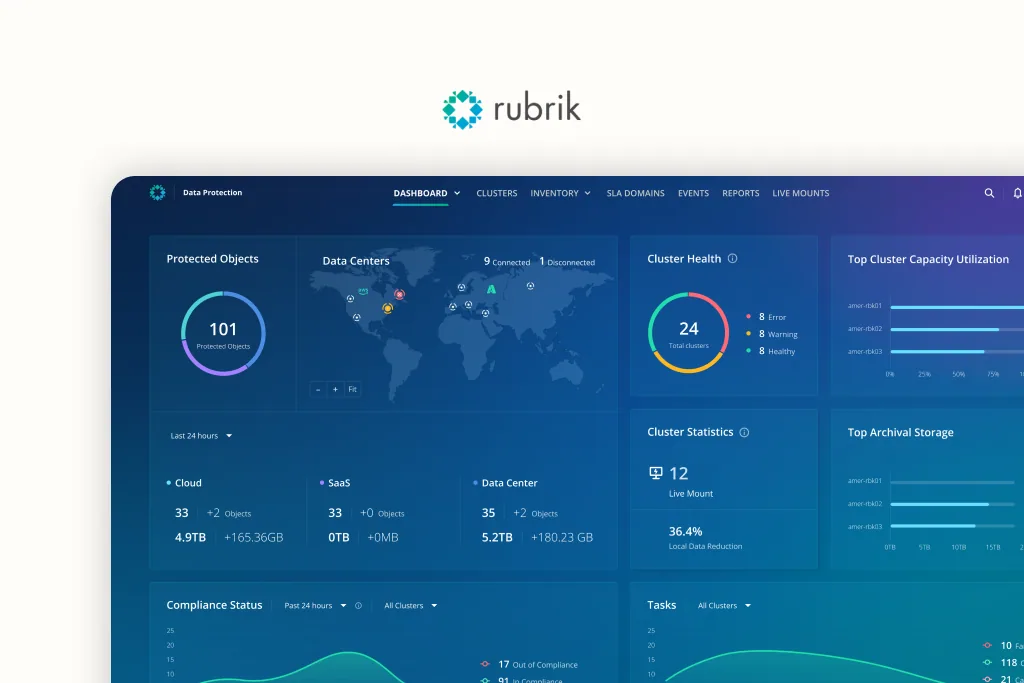
Rubrik is enterprise data security infrastructure — a backup-and-recovery layer that protects data against ransomware, hardware failure, and outages, and lets companies restore from clean snapshots when something goes wrong. The people who use it every day are IT / data admins managing clusters of backup nodes (effectively storage hardware running Rubrik software), monitoring health, scheduling jobs, replacing disks, and triaging alerts.
Rubrik's pre-IPO push was migrating customers from the on-prem legacy console (CDM) to the new cloud platform (RSC), but RSC had prioritized new ransomware detection while day-to-day monitoring stayed underdeveloped — so 85% of customers stayed on the old tool.
How do we give those admins a reason to migrate, when "familiar and works" beats "new and missing things"?
Powered Rubrik's 2024 IPO
Migrated 85% of customers off the legacy on-prem console to Rubrik Security Cloud, drove a 12× increase in user engagement, and reduced support cases by 70%. Cited as 'the most successful and crucial groundwork transformation' by Rubrik's CPO; recognized with a Red Dot Design Award.
Not a dashboard problem.
The brief I inherited was "redesign the data-monitoring dashboard." But day-to-day operations on the legacy console — cluster jobs, health, disk replacement — were already mature. The SaaS replacement had been deprioritized because cloud-native ransomware features were the post-IPO storyline, not maintenance UX. The actual reason 85% of customers stayed on CDM wasn't that the new dashboard looked dated; it was that the new dashboard couldn't do the day job yet.
I reframed the brief from "redesign the dashboard" to "give admins a reason to migrate without losing what they already trust." Same surface, completely different success criteria.
“It wasn't a dashboard problem. It was a migration problem.”
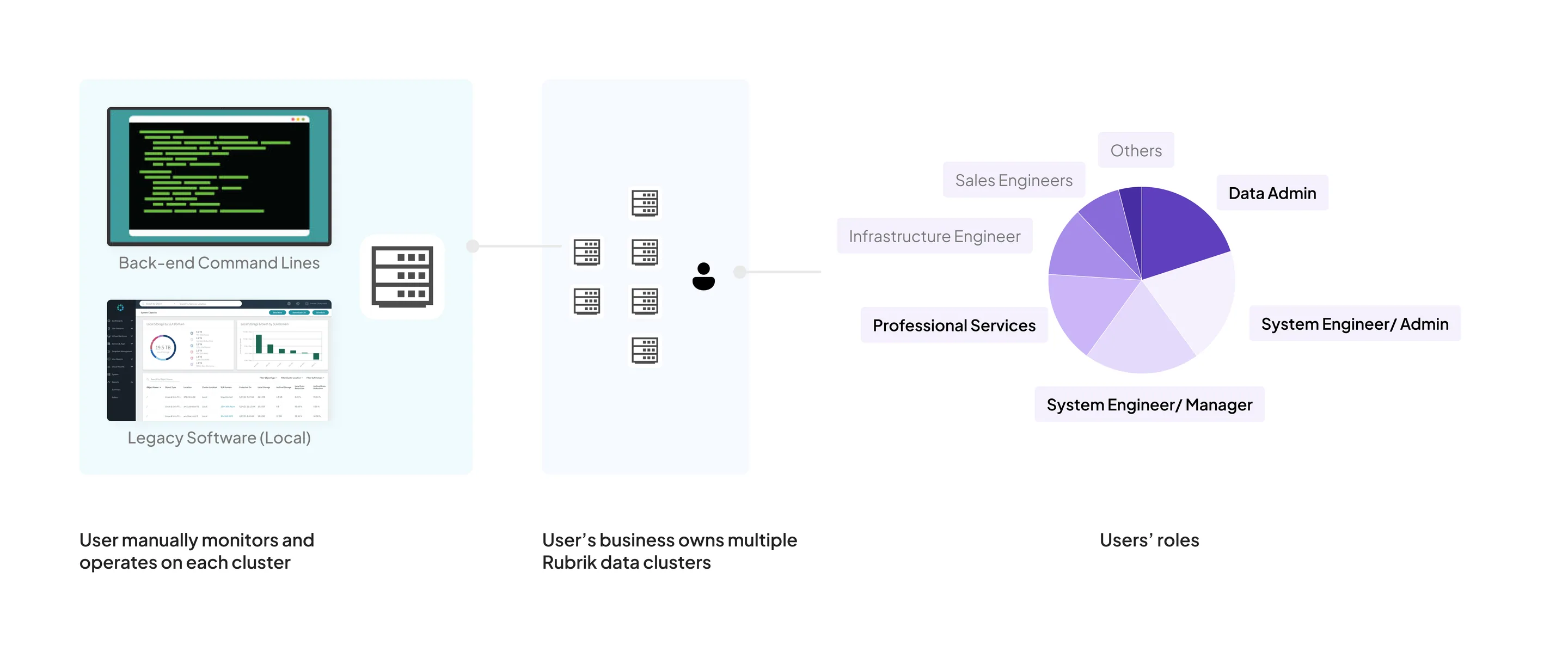
Five operational stages, not one workflow.
I ran 90-minute exploratory interviews across small, medium, and large enterprise customers and MSPs (Managed Service Providers, who run Rubrik on behalf of their own customers). The journey-mapping work surfaced 5 distinct operational stages — onboarding, fleet monitoring, cluster operations, hardware lifecycle, incident response — each with different mental models and different failure modes.
That finding is what justified the four-tier architecture. One unified dashboard couldn't serve all five stages without compromising every one of them; the contextual tiers let each stage have a surface designed against its actual mental model.
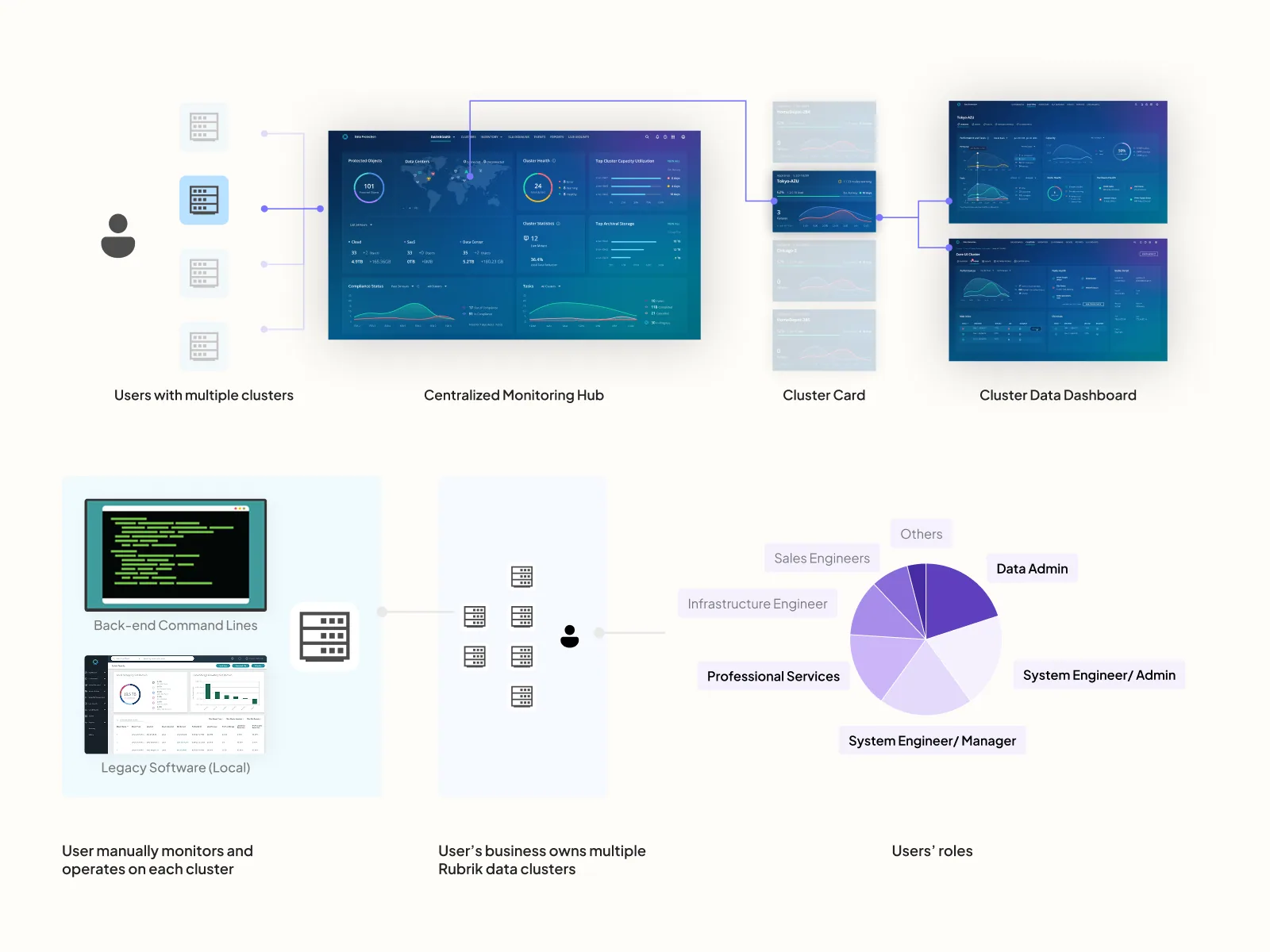
From one cluster, one console to one pane for the fleet.
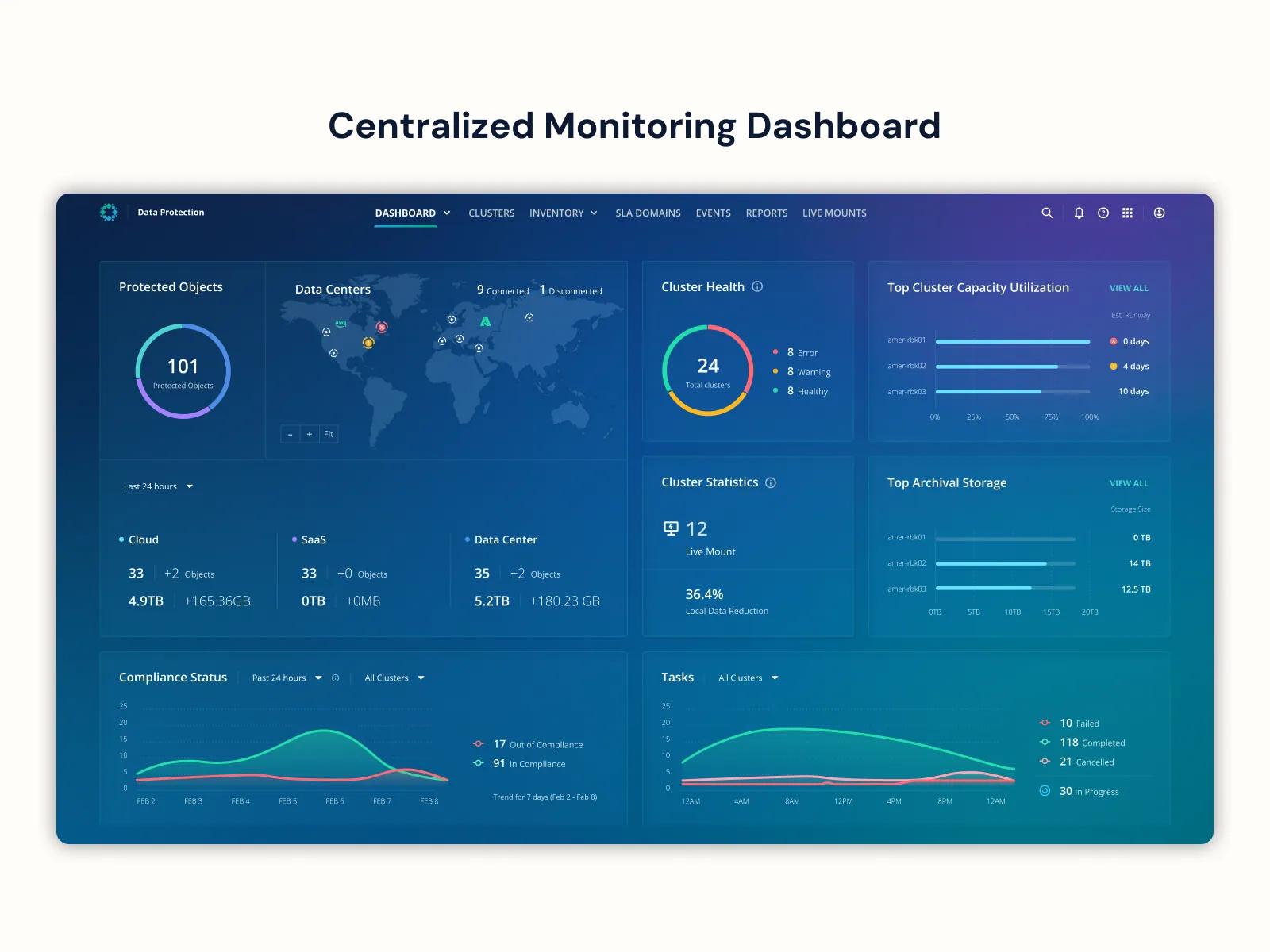
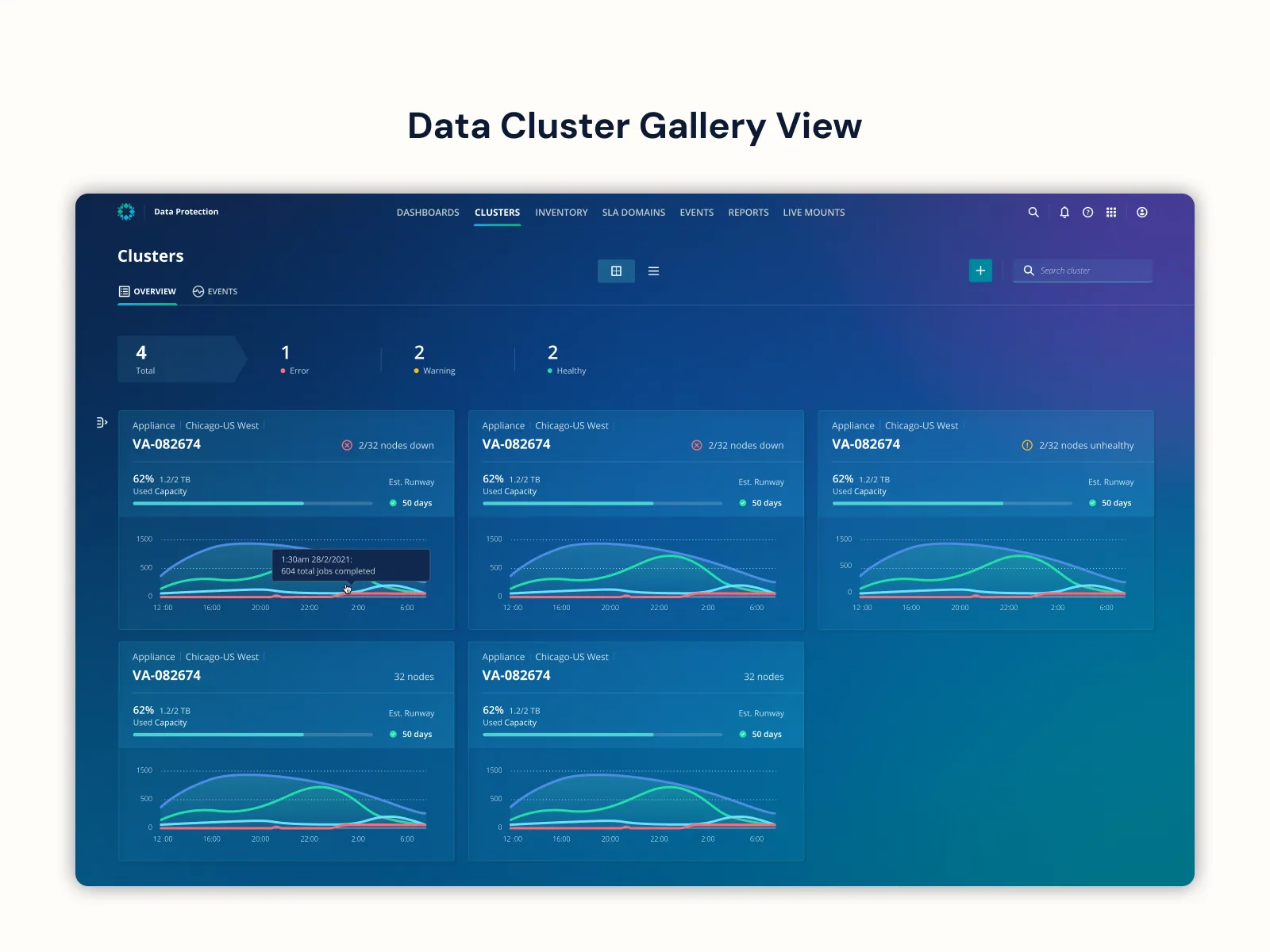
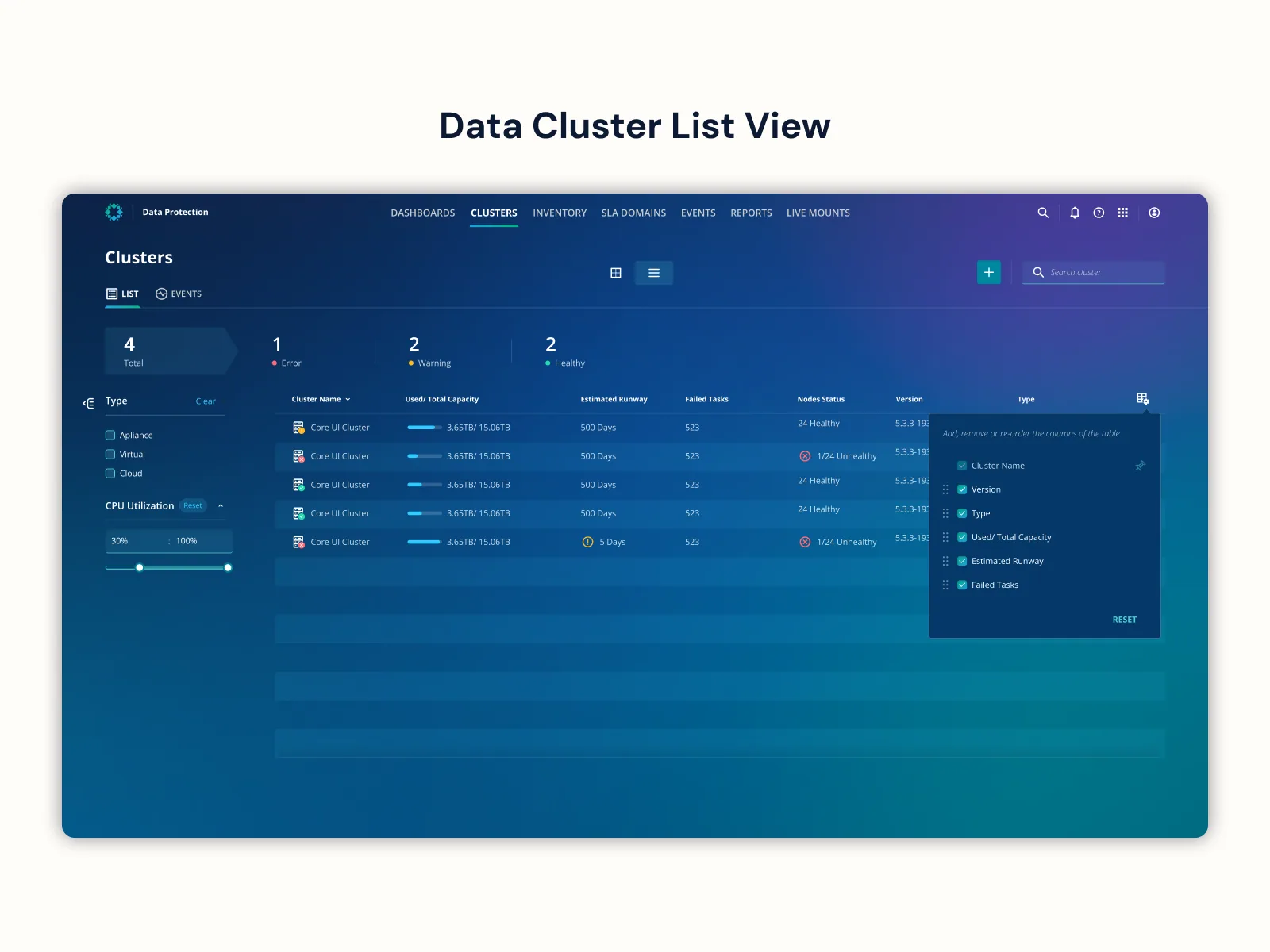
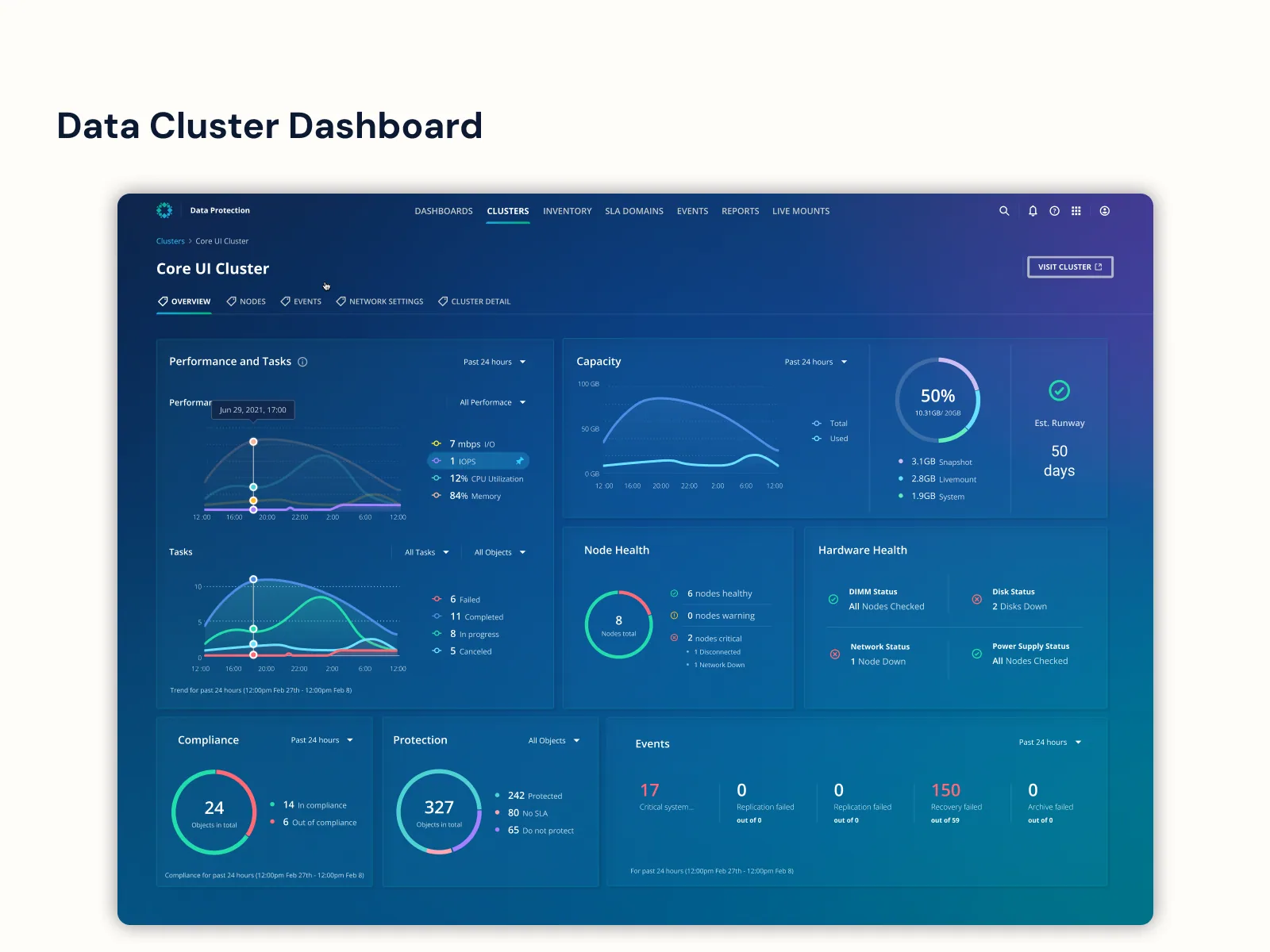
I restructured the platform from one-monitoring-center-per-cluster into a centralized multi-cluster monitoring hub with four contextual tiers — Global Dashboard → Cluster Gallery → Cluster Dashboard → Hardware Operational Dashboard. A single pane that scales from fleet-wide health down to a specific failing node, with drill-down logic that respects how admins actually triage.
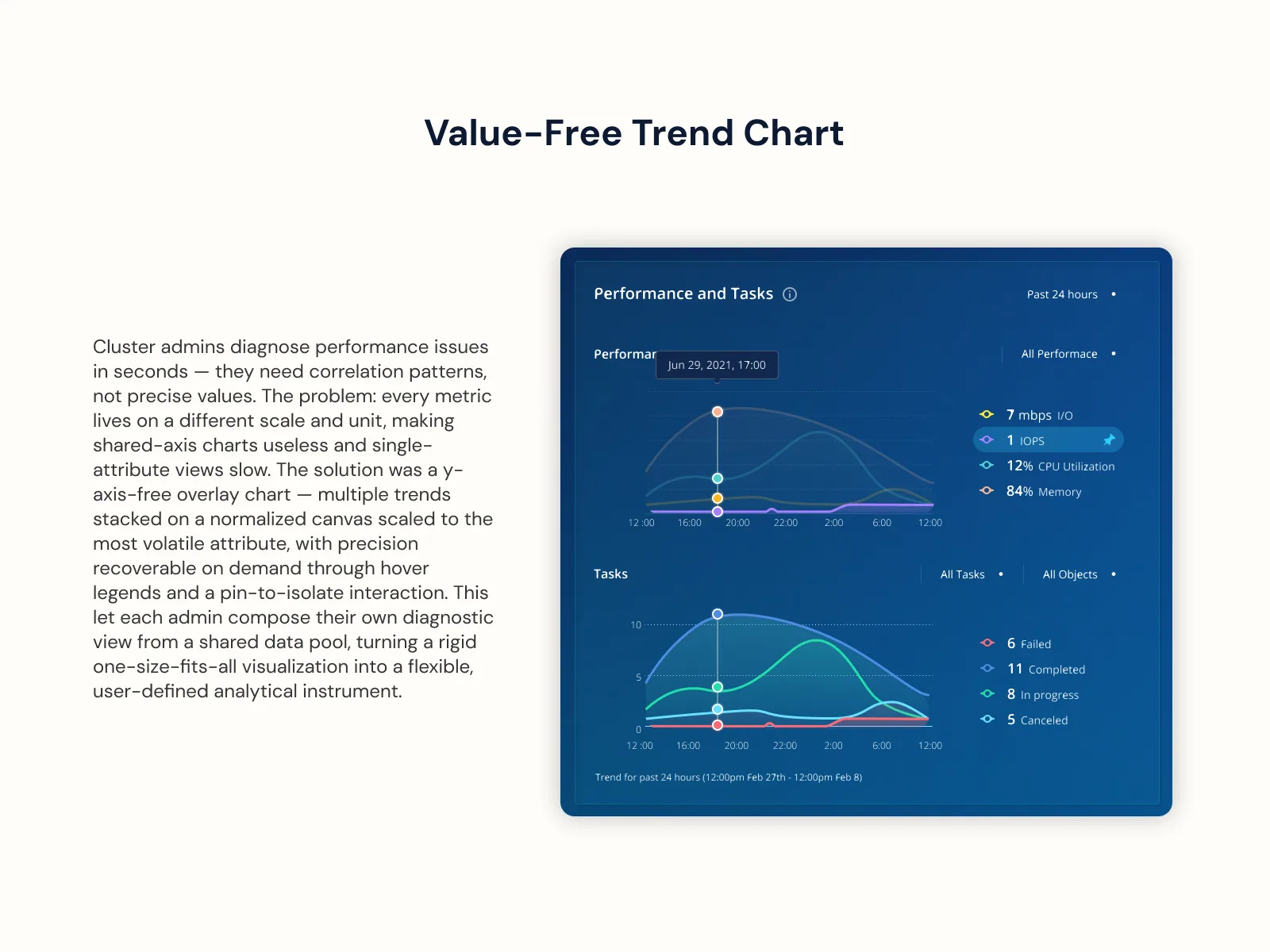
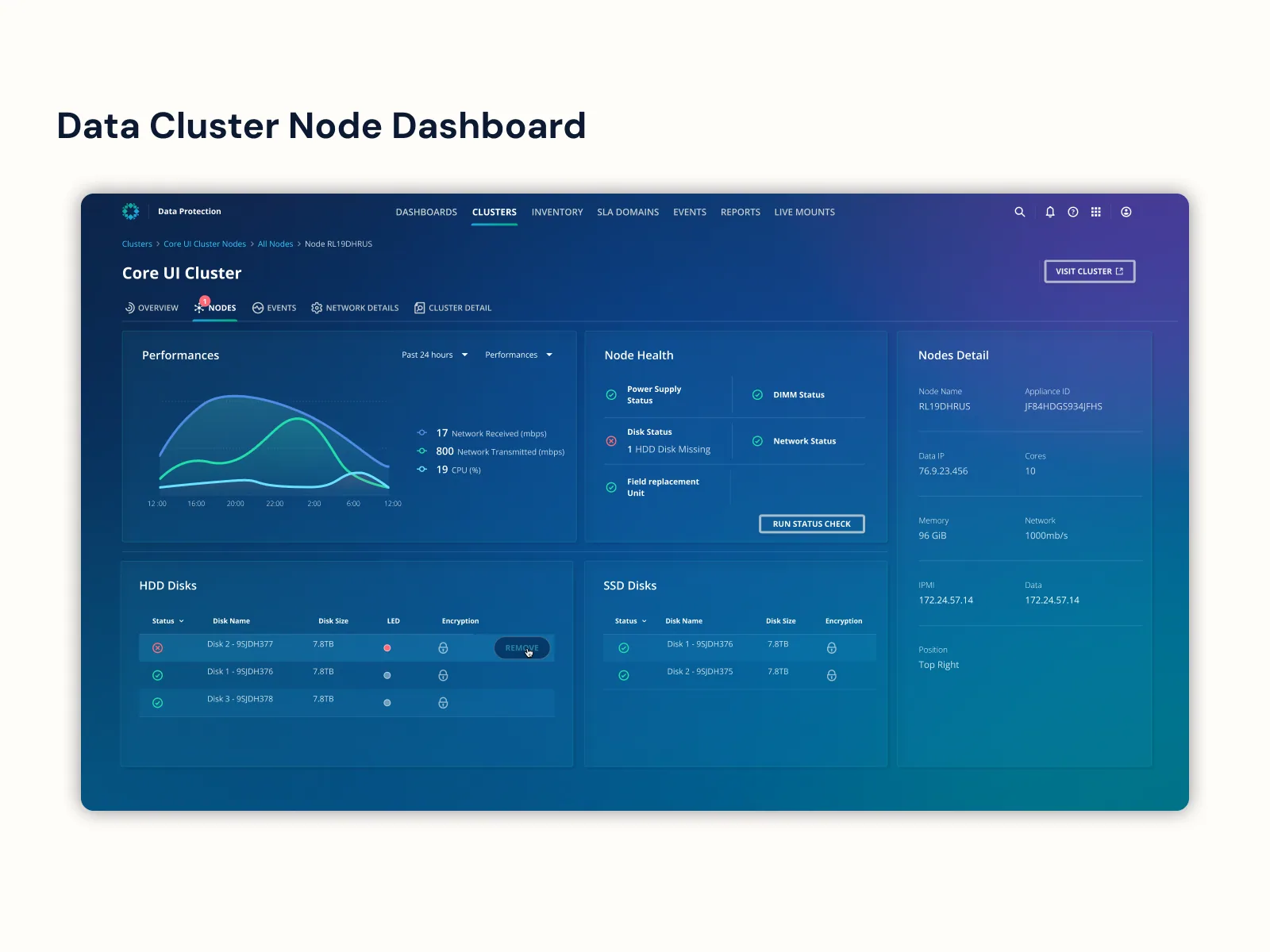
The Hardware Operational Dashboard was the CLI-to-UI moment of the redesign: 15 backend-only access points became 7 interactive UI views, and 17 net-new data points got visualized for the first time. Power users still wanted CLI-style density; new ones wanted a pane that explained itself. Progressive disclosure handled both, validated against admin shadowing sessions.
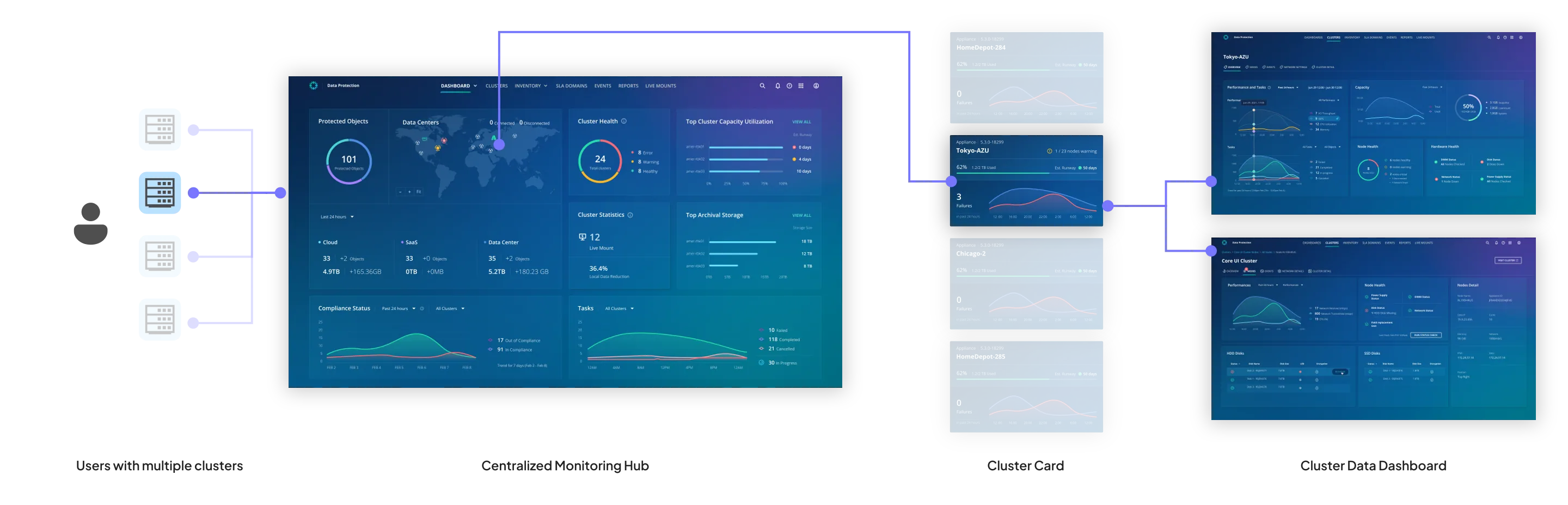
The Centralized Hub view — the multi-cluster monitoring tier that lets a single admin see fleet-wide health and drill into any individual cluster's operations from one pane. Scroll horizontally to walk the full surface.
Where I made the calls.
- 01Diagnosed the customer-stickiness problem at brief level. Day-to-day operations (cluster jobs, health, disk replacement) were mature on the legacy console; the SaaS replacement had been deprioritized in favor of cloud-native ransomware features. Reframed the brief from 'redesign the dashboard' to 'give admins a reason to migrate without losing what they already trust.'
- 02Restructured the platform from one-monitoring-center-per-cluster into a centralized multi-cluster monitoring hub with four contextual tiers (Global Dashboard → Cluster Gallery → Cluster Dashboard → Hardware Operational Dashboard) — a single pane that scales from fleet-wide health down to a specific failing node.
- 03Translated 15 CLI-only operations into 7 interactive UI views — the Hardware Operational Dashboard in particular brought backend-only access points into a visual interface for the first time. Visualized 17 net-new data points across the surfaces.
- 04Ran 90-minute exploratory interviews across small / medium / large enterprise and MSP customers; the journey-mapping work surfaced 5 distinct operational stages with different mental models, which became the structural rationale for the four contextual tiers.
- 05Designed progressive disclosure for power users (who wanted CLI-style density) alongside sensible defaults for new ones (who wanted a pane that explained itself), validated against admin shadowing sessions.
Migration design is respect work.
Replacing a tool people already trust is a different kind of design problem from building one from scratch. The design move that worked here was acknowledging the legacy console's strengths first, then building the new surfaces against that mental model — not against the new feature taxonomy that the cloud team was excited about.
The thing I'd port forward to any future migration project: the user's muscle memory is real ROI. Throwing it away to ship "a fresh take" is how you get the on-paper redesign that 85% of customers refuse to use.